
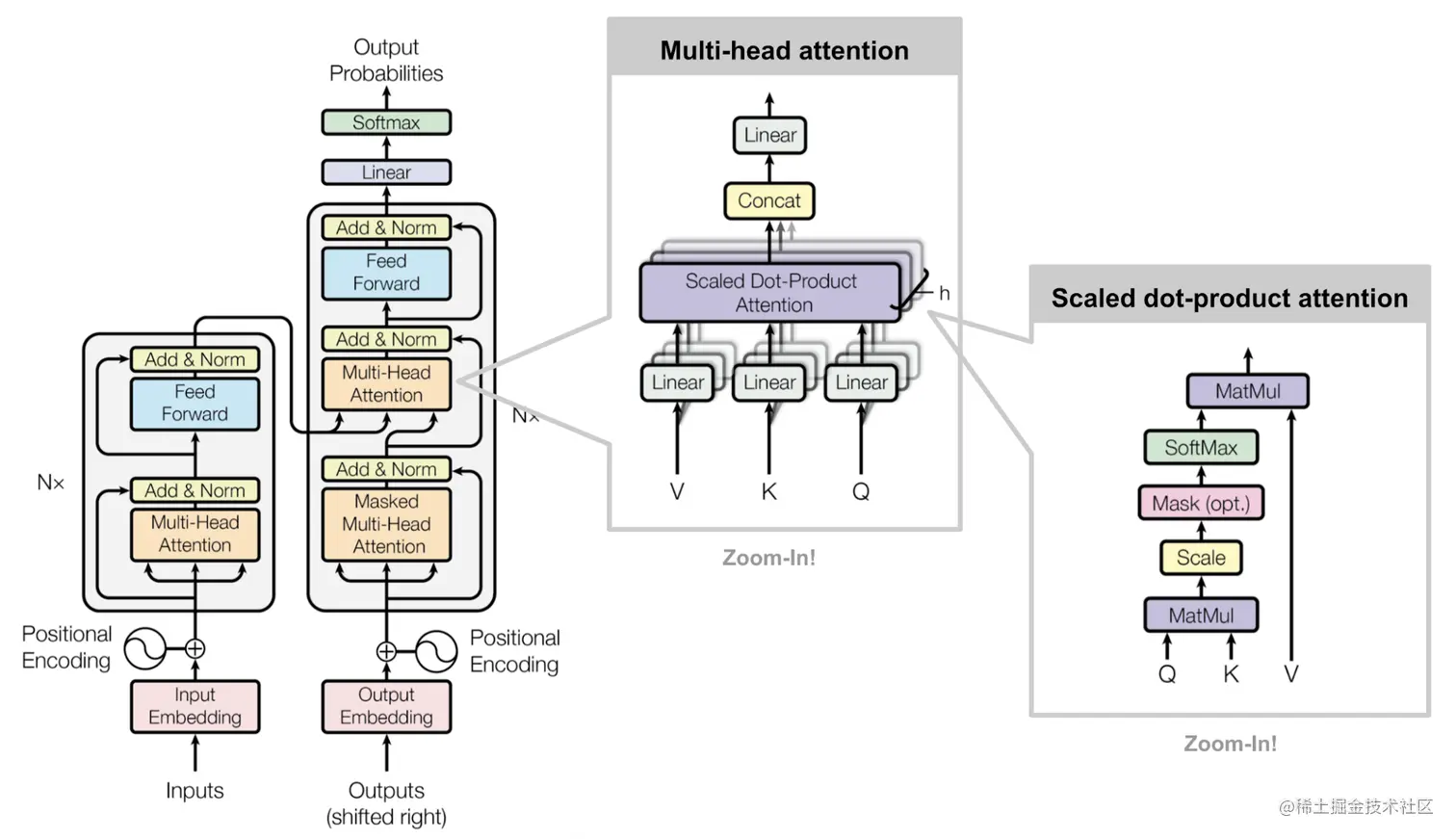
為什麼torch.nn.transformer中每個input的feature size需要是head數量的倍數
前言
在第一次新生訓練時,學長有講解有關transformer的架構,而講解完後,他留了一個小作業,也就是關於 multi-head transformer在pytorch中的實作中,d_model需要被nhead整除,d_model是指說input的feature size,nhead是指說head的數量。這個結果好像跟理論上有些落差,並要我們解釋原因。
Multi-Head Transformer 理論
在學長的講解過程中,有提到對於Multi-Head Transformer是對同一個input做了很多個Self-Attention後,再將多次輸出連接在一起後,再和一個大矩陣相乘,壓回原本的大小,這個過程也就是做加權平均。具體過程如下兩張圖。
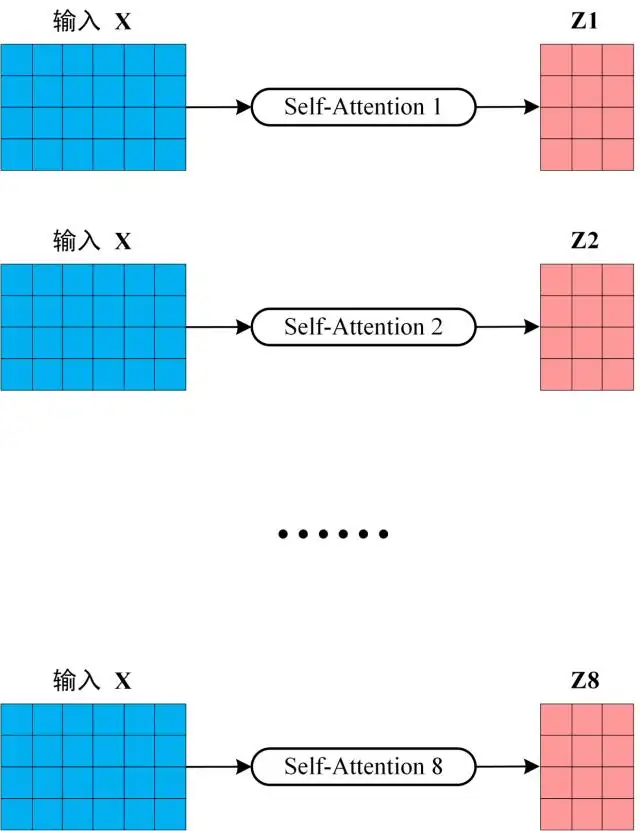
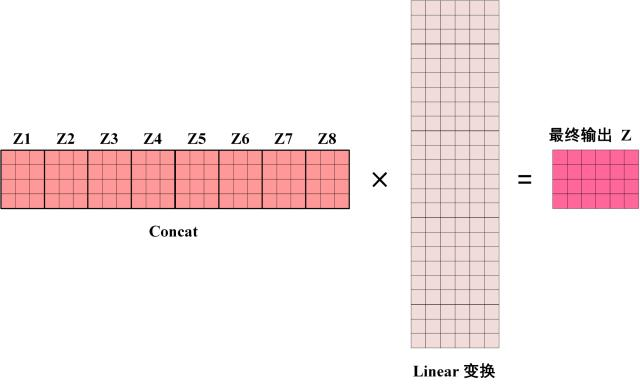
而上述的過程中,我們會發現無論輸入x的size是多少,都與head的數量無關,也就是說不論feature size和head數量是多少,理論上都能訓練得起來。
為什麼torch.nn.transformer中d_model需要被nhead整除
上個段落講說其實feature size和head數量無關,但如果對nn.transformer填入任意的feature size和head數量,可能會被提示說feature size需為head數量的倍數。

至於為什麼,現在慢慢trace source code。
首先先看到nn.transformer: https://pytorch.org/docs/stable/_modules/torch/nn/modules/transformer.html#Transformer
其中與nhead和d_model相關的部分則是TransformerEncoderLayer這個class。
1 | |
所以繼續看class TransformerEncoderLayer到底寫了什麼,我們發現在class TransformerEncoderLayer中與d_model和nhead相關的class為MultiheadAttention。
1 | |
為了繼續trace code,我又在網路上找了class MultiheadAttention: https://pytorch.org/docs/stable/_modules/torch/nn/modules/activation.html#MultiheadAttention
仔細看,他又把forward的過程丟給了F.multi_head_attention_forward。
1 | |
所以我們再去看F.multi_head_attention_forward寫了什麼: https://github.com/pytorch/pytorch/blob/main/torch/nn/functional.py
1 | |
首先會看到他寫了nhead必須要被embed_dim整除,然後整除後的變數叫做head_dim。
然後順著有head_dim變數的地方找,發現在最後一段中,qkv都變成了4維陣列,再丟進scaled_dot_product_attention運算。
可以仔細觀察四維陣列形狀,分別都是由(batch size, number of head,
target/source length, head
dimension)組成。如果根據上一段的理論來說,格式應該是(batch size,
target/source length, feature size = number of head * head
dimension)。在這不難看出qkv變成了4維陣列的理由,就是單純對target/source
length, head dimension做矩陣乘法運算,而number of
head那個dimension就像是batch size那個dimension一樣,完全不受影響。
簡潔來說torch.nn.transformer的multi-head實作,透過將feature size平均拆成多份,並將每份分給不同的head做運算,最後再接起來。這種作法的好處就是可以在稍微影響效能的情形下,省去大量的運算,因為每個input平均分給不同的head計算,不會有重複餵input再加權平均的情況發生。假如multi-head是8的話,torch.nn.transformer在這部分減少了約7/8的計算量。
心得
在這次trace code的過程中,除了發現理論和實作上的差距,我還發現官方的code,oop寫的比我在交大修的任何AI課還要嚴謹許多,完全不是單純把model刻出來就結束了。在封裝上也很漂亮,也寫了許多assert來規範奇怪的輸入。透過trace code的過程,也能學習到良好的coding習慣。